RAG에 관심을 갖고 공부하던 중 흥미로운 논문이 있어 정리하게 되었습니다.
Abstract
이 논문은 대규모 언어 모델(LLM)을 훈련하는 표준 방법에 대한 새로운 접근인 "Retrieval Augmented Fine Tuning (RAFT)"을 제안합니다. RAFT는 사전 훈련된 모델에 새로운 지식을 추가하기 위한 방법으로, "open book" 도메인 설정에서 모델이 질문에 답하는 능력을 향상시킵니다. 이를 위해 RAFT는 질문과 검색된 문서 세트를 사용하여 모델을 훈련시키는데, 이때 "distractor document"를 무시하도록 학습됩니다. RAFT는 올바른 시퀀스를 인용함으로써 모델이 도움이 되는 정보를 찾는 능력을 강화합니다. 논문에서는 RAFT를 적용하여 PubMed, HotpotQA, Gorilla 데이터셋에서 모델의 성능을 향상시키는 실험을 보여줍니다. RAFT의 코드 및 데모는 https://github.com/ShishirPatil/gorilla에서 오픈 소스로 제공됩니다.
1. Introduction
최근 대규모 언어 모델(LLMs)이 일반적인 지식 추론 작업에서 큰 발전을 이루어 왔습니다(Brown et al., 2020; Wei et al., 2022). 그러나 이제 LLMs는 특정 소프트웨어 프레임워크의 코드 완성부터 특정 문서 모음(예: 법적 또는 의료 문서)에 대한 질문 응답까지 다양한 특화 도메인에서 사용되고 있습니다. 이러한 상황에서는 일반적인 지식 추론보다는 주어진 문서 세트를 기반으로 정확도를 극대화하는 것이 주요 목표입니다. 특화된 도메인에 LLMs를 적응시키는 것은 많은 신흥 응용 프로그램에 중요하며, 이 논문은 이를 주요 관심사로 삼고 있습니다.
이 논문에서는 사전 훈련된 LLMs를 특화된 도메인에서 검색 증강 생성(RAG)을 위해 어떻게 적응시킬지에 대해 다룹니다.
특화된 도메인에 LLMs를 적응시키는 경우, 두 가지 후보 방법을 고려합니다: 문맥 중심 학습을 통한 RAG 기반 방법과 supervised fine-tuning. RAG 기반 방법은 문서를 참조하여 질문에 답변할 수 있게 합니다. 하지만 이 방법은 고정된 도메인 설정과 테스트 문서에 대한 초기 학습 기회를 제대로 활용하지 못합니다. 반면, supervised fine-tuning은 문서에서 더 일반적인 패턴을 학습하고 최종 작업 및 사용자 기호에 더 잘 부합시킬 수 있는 기회를 제공합니다(Zhou et al., 2023a). 그러나 기존의 fine-tuning 기반 방법은 test시 문서를 활용하지 못하거나(즉, RAG를 포함하지 않음) 훈련 중 검색 과정의 불완전성을 고려하지 못합니다.
논문에서는 이를 open book 시험에 비유합니다. 기존의 문맥 중심 검색 방법(RAG)은 공부하지 않은 채로 오픈북 시험을 보는 것으로 비유될 수 있습니다. 반면, 기존의 fine-tuning 기반 방법은 문서를 직접 "암기"하거나(Wang et al., 2022) 문서를 참조하지 않고 연습 문제에 답하는 것으로 "공부"를 대체하는 것으로 비유됩니다. 이러한 방법은 도메인 내 학습을 활용하지만 시험 환경의 오픈북 성격을 준비하지 못합니다.
이 논문에서는 지도된 파인튜닝(SFT)과 검색 증강 생성(RAG)을 결합하는 방법을 연구하고 있습니다. 새로운 적응 전략인 "검색 증강 파인튜닝(RAFT)"을 제안합니다. RAFT는 LLMs를 특정 도메인에 파인튜닝하고 동시에 도메인 내 RAG 성능을 향상시킵니다. 이 방법은 모델이 파인튜닝을 통해 도메인별 지식을 학습할 수 있도록 하면서도 훈련 중 검색의 불완전성에 대응하여 모델을 견고하게 만듭니다. 이는 모델이 제시된 질문(프롬프트), 검색된 도메인 특정 문서, 적절한 답변 간의 동적 관계를 이해하도록 모델을 훈련시킵니다.

RAFT에서는 모델을 문서(D*)에서 질문(Q)에 대한 답변을 생성하도록 훈련합니다. 이 때 답변(A*)은 사고의 연결을 포함하며(Wei et al., 2022; Anthropic, 2023), 방해 요소 문서(distractor document, Dk)가 존재하는 상황에서 수행됩니다.
우리는 섹션 3에서 방법론을 자세히 설명하고, 섹션 5에서 훈련 및 테스트 시간에 방해 요소 문서(k)의 민감도를 분석합니다. RAFT는 PubMed(Dernoncourt & Lee, 2017), HotpotQA(Yang et al., 2018) 및 HuggingFace Hub, Torch Hub 및 Tensorflow Hub Gorilla 데이터셋(Patil et al., 2023)을 통해 검색 증강 생성과 관련하여 SFT보다 일관되게 우수한 성능을 발휘하여 사전 훈련된 LLMs를 도메인 내 RAG에 대해 개선하는 새로운, 그러나 간단한 기술을 제시합니다.
2. LLMs for Open-Book Exam
이해를 돕기 위해, 시험을 준비하는 현실 세팅에서 LLM을 훈련시키는 것 사이의 유사성에 대해 더 자세히 설명하겠습니다.
Closed-Book Exam
Closed-book 시험은 LLMs가 추가 문서나 참고 자료에 액세스할 수 없는 상황에서 질문에 답해야 하는 것을 의미합니다. 이것은 챗봇으로 사용되는 상황과 유사합니다. 이러한 상황에서 LLM은 사전 훈련 중에 통합된 지식과 supervised fine-tuning 과정에서 얻은 지식을 활용하여 프롬프트에 응답합니다. 쉽게 말해, SFT와 같습니다.
Open Book Exam
오픈북 시험 환경에서는 LLM이 외부 정보원을 참고할 수 있으며, 일반적으로 리트리버와 함께 사용됩니다. 리트리버는 'k'개의 문서를 검색하여 프롬프트에 첨부합니다. LLM은 이러한 검색된 문서를 통해 새로운 지식에 액세스합니다. 따라서 LLM의 성능은 주로 리트리버의 품질과 가장 관련성 높은 정보를 얼마나 정확하게 식별할 수 있는지에 따라 결정됩니다.
쉽게 말해, RAG와 같습니다.
Domain Specific Open-Book Exam
본 논문은 일반적인 도메인별 오픈북 시험에 초점을 맞추고 있습니다. 이때 LLM은 테스트될 도메인을 사전에 알고 있으며, 해당 도메인에서 미세 조정된 정보를 사용하여 프롬프트에 응답합니다. 예를 들어, 기업 문서, 최신 뉴스, 조직의 코드 저장소와 같은 특정 도메인이 있습니다. 이러한 환경에서 LLM은 문서 모음(작은 실제 도메인) 내에서 답변을 찾을 수 있는 질문에 응답하기 위해 사용됩니다. 검색 기술은 주로 메커니즘에 영향을 미치지 않지만 정확도에는 영향을 줄 수 있습니다. 논문은 이러한 도메인별 오픈북 환경을 연구하며, 사전 훈련된 LLM을 특정 도메인에 적응시키는 방법과 검색된 문서 및 방해 요소의 수가 변할 때 더 견고하게 만드는 방법에 대해 다룹니다. 간단히 말해, RAFT와 같습니다.
3. RAFT
이 섹션에서는 도메인별 오픈북 시험을 위해 LLMs를 훈련시키는 새로운 방법인 RAFT를 제시합니다. 먼저, 고전적인 기술인 SFT를 소개하고 실험 결과를 요약합니다. 그런 다음 RAFT를 소개하고 일반적인 지시어 튜닝의 수정된 버전을 설명합니다. 마지막으로, 이후 섹션에서 기대할 수 있는 실험 개요를 제공합니다.

Supervised Finetuning
지도된 파인튜닝(SFT) 설정에서는 질문-답변 데이터셋에 기반하여 모델을 훈련시킵니다. 이 설정에서는 주어진 데이터셋(D)에서 질문(Q)과 해당 답변(A) 쌍이 사용됩니다. 고전적인 SFT 설정에서는 모델이 질문에 대한 답변 능력을 향상시키기 위해 훈련됩니다. 이는 사전 훈련 중이든 SFT 훈련 중이든지 얻은 지식을 기반으로 합니다. 이렇게 훈련된 모델은 테스트 시간에 추가 문서를 프롬프트에 도입하여 모델이 질문에 답할 수 있도록 돕는 검색 증강 생성(RAG) 설정에서도 사용될 수 있습니다.

RAFT
검색 인식 파인튜닝(RAFT)은 도메인 내 RAG에 해당합니다. RAFT에서는 각 데이터 포인트가 질문(Q), 문서 세트(Dk), 그리고 문서(D*) 중 하나에서 생성된 답변(A∗)을 포함하도록 훈련 데이터를 준비합니다. '오라클' 문서(D*)와 '방해 요소' 문서(Di) 두 가지 유형의 문서를 구분합니다. 오라클 문서는 질문에 대한 답을 유추할 수 있는 문서이며, 방해 요소 문서는 답과 관련이 없습니다. 구현 세부 사항으로, '오라클' 문서는 단일 문서일 필요는 없으며, 가령 HotpotQA (Yang et al., 2018)의 경우 여러 문서일 수 있습니다.
그런 다음 데이터셋의 P%의 질문(qi)에 대해 오라클 문서(di*)를 유지하고 방해 요소 문서(dk-1)를 포함합니다. 데이터셋의 (1 - P)%의 질문(qi)에 대해서는 오라클 문서를 포함하지 않고 방해 요소 문서만 포함합니다.
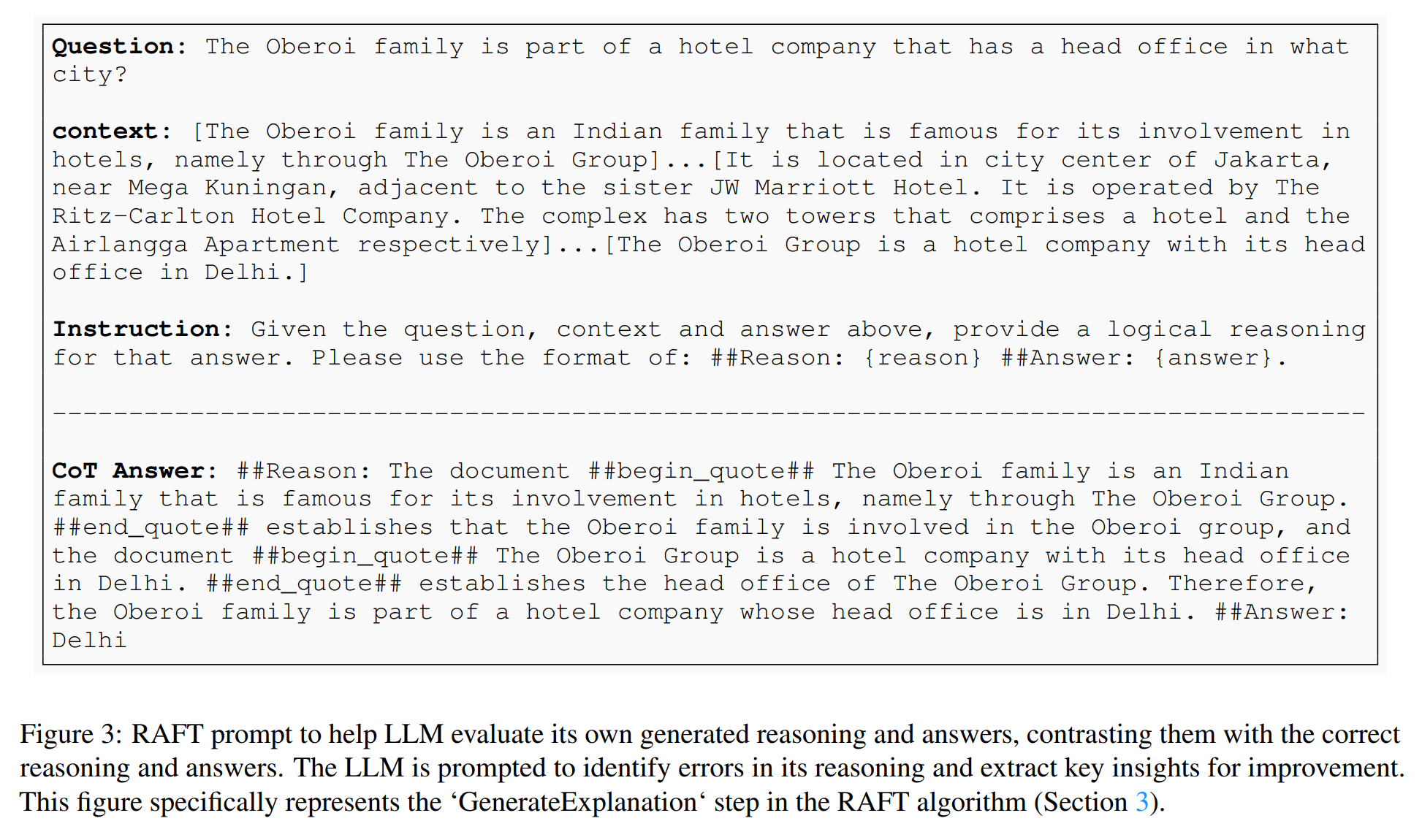
이러한 데이터셋은 표준 지도 학습(SFT) 기술을 사용하여 언어 모델을 파인튜닝하여 제공된 문서와 질문에서 답변을 생성하도록 합니다. RAFT의 접근 방식은 모델이 훈련된 문서 세트에서 RAG를 더 잘 수행하도록 만듭니다. 때로는 오라클 문서를 제거하여 모델이 답변을 추출하는 대신 답변을 기억하도록 만듭니다. RAFT의 훈련 데이터는 질문, 문서 세트, 오라클 문서, 방해 요소 문서로 구성되며, 이는 그림 3에서 시각적으로 확인할 수 있습니다.

테스트 시나리오에서는 모델에게 RAG 파이프라인에 의해 검색된 상위 k개의 문서와 함께 질문(Q)이 제공됩니다. RAFT는 사용된 리트리버와 독립적이며, 훈련 품질을 향상시키는 데 중요한 요소 중 하나는 Chain-of-Thought와 같은 추론 과정을 생성하는 것입니다. RAFT 접근 방식은 이러한 추론 체인을 생성하고, 소스를 명확하게 인용함으로써 모델이 질문에 대한 정확도를 높일 수 있음을 보여줍니다. 그림 3에서 이것을 설명합니다. 이 방식으로 훈련 데이터를 생성하는 것은 모델에게 질문, 문맥 및 확인된 답변을 제공하고, 원래 문맥을 적절하게 참조하는 추론 체인을 형성하도록 요청하는 것을 포함합니다. 실험에서는 이 기술을 사용하여 모든 데이터셋에서 답변을 생성하며, Gorilla APIBench 데이터셋은 이미 답변에 추론을 포함하고 있습니다. 그림 3에서는 생성 단계의 예를 제공하며, 자세한 추론 답변에는 ##begin_quote## 및 ##end_quote## 내의 원래 문맥에서의 인용뿐만 아니라 그 인용을 기반으로 결론에 도달하는 방법에 대한 설명이 포함됩니다. 실험 섹션에서는 자세한 추론 단락을 추가하는 것이 모델의 성능을 향상시키는 데 도움이 된다는 것을 보여줍니다.
4. Evaluation
이 실험에서는 RAFT가 다양한 베이스라인과 비교하여 얼마나 잘 수행되는지 연구하기 위해 실험을 설계했습니다. RAFT7B 모델(LlaMA-2의 파인튜닝 버전)이 도메인 특정 파인튜닝 모델 및 RAG를 사용하는 일반적인 목적 모델보다 도메인 내 문서에서 정보를 더 잘 읽고 추출하는 것으로 나타났습니다. 또한 제거 실험으로 모델이 Chain-of-Thought 응답과 함께 학습하는 것이 얼마나 중요한지를 보여줍니다. 이 섹션에서는 실험에서 사용된 모든 데이터셋을 먼저 소개하고, 그 후 벤치마크 대상이 되는 모든 베이스라인 모델과 파인튜닝 기술을 소개할 것입니다.
4.1. Datasets
실험에서는 모델과 다양한 베이스라인을 평가하기 위해 다음 데이터셋을 사용합니다. 데이터셋은 위키백과, 코딩/API 문서, 그리고 의료 문서에 대한 질문-답변으로 구성됩니다.
• Natural Questions (NQ) (Kwiatkowski et al., 2019), Trivia QA (Joshi et al., 2017) 및 HotpotQA (Yanget al., 2018)는 위키피디아를 기반으로 한 오픈 도메인 질문-답변 데이터셋으로, 주로 일반 지식(예: 영화, 스포츠 등)에 중점을 둡니다.
• HuggingFace, Torch Hub 및 TensorFlow Hub은 Gorilla 논문에서 제안된 APIBench (Patil et al., 2023)의 일부입니다. 이 벤치마크는 문서를 기반으로 올바른, 기능적 및 실행 가능한 API 호출을 생성하는 방법을 측정합니다.
• PubMed QA (Jin et al., 2019)는 의료 연구 질문-답변에 특화된 데이터셋입니다. 이는 의료 및 생물학 질문에 답하는 데 중점을 둡니다.
첫 번째 데이터셋 범주(NQ, Trivia QA 및 HotpotQA)는 비교적 일반적인 도메인에 속하는 반면, 후자 두 도메인은 매우 도메인 특화된 문서에 관한 것임을 유의하십시오.
Baselines 우리의 실험에서는 다음과 같은 베이스라인을 고려합니다:
• 0-shot 프롬프팅을 사용한 LlaMA2-7B-chat 모델: 이는 QA 작업에 일반적으로 사용되는 지시어 파인튜닝 모델로, 명확하게 작성된 지시사항을 제공하지만 참고 문서는 제공하지 않습니다.
• RAG를 사용한 LlaMA2-7B-chat 모델 (Llama2 + RAG): 이전 설정과 유사하지만 여기에는 참고 문서가 포함됩니다. 이는 도메인 특정 QA 작업을 다룰 때 인기 있는 기술입니다.
• 0-shot 프롬프팅을 사용한 도메인 특정 파인튜닝(DSF): 문맥에서 문서를 포함하지 않고 표준 지도 학습 파인튜닝을 수행합니다. 이는 모델의 답변 스타일을 조정하고 도메인 컨텍스트에 익숙해지는 데 주로 유용합니다.
• RAG를 사용한 도메인 특정 파인튜닝 (DSF + RAG): RAG를 사용하여 외부 지식을 도메인 특정 파인튜닝 모델에 제공합니다. 따라서 모델이 모르는 "지식"의 경우에도 컨텍스트를 참고할 수 있습니다.
4.2. Results
위의 데이터셋과 베이스라인을 사용하여, RAFT 모델을 평가하고 결과를 Table 1에서 보여줍니다. RAFT는 일관되고 유의미하게 베이스라인을 능가합니다. 특히, RAG를 사용한 RAFT는 정보 추출 측면에서 우수하며 방해 요소에 대해 더 강건합니다. 이로 인해 Hotpot QA에서 최대 35.25%, Torch Hub에서 76.35%까지 성능 향상이 있습니다. 또한, 특정 데이터셋에서 DSF(domain specific fine-tuning)와 비교했을 때, RAFT는 문제를 해결하기 위해 제공된 문맥에 더 의존하여 더 나은 결과를 보입니다. RAFT는 HotpotQA 및 HuggingFace 데이터셋과 같은 작업에서 훨씬 우수한 성능을 보여주며, PubMed QA의 경우에는 이진 예/아니오 질문이기 때문에, DSF+RAG와 비교했을 때 유의미한 이득을 관찰하지 못합니다. GPT-3.5와 비교했을 때도 RAFT는 상당한 장점을 보입니다.

전체적으로, LLaMA-7B 모델은 RAG를 사용하여도 그 답변 스타일이 실제와 일치하지 않아 성능이 낮습니다. 그러나 도메인 특정 파인튜닝을 통해 성능을 크게 향상시킬 수 있습니다. 이 과정을 통해 모델은 적절한 답변 스타일을 학습하고 채택할 수 있습니다. 하지만 도메인 특정 파인튜닝(DSF) 모델에 RAG를 도입하는 것이 항상 더 나은 결과를 보장하지는 않습니다. 이는 모델이 맥락 처리와 유용한 정보 추출에 대한 훈련이 부족함을 시사할 수 있습니다. 우리의 RAFT 방법론을 통합함으로써, 모델은 필요한 답변 스타일과 일치하도록 훈련되는 동시에 문서 처리 능력도 향상됩니다. 결국, RAFT 접근 방식은 다른 모든 방법보다 우수한 성과를 보입니다.
4.3. Effect of CoT
Chain-of-Thought 접근 방식이 모델 성능 향상에 얼마나 효과적인지 평가하기 위해 분석을 실시했습니다. 결과적으로, 질문에 대한 답변만 제공하는 것은 항상 충분하지 않을 수 있습니다. 이는 Table 2에 나타납니다. 이러한 방식은 손실이 급속히 감소하여 훈련 과정이 발산할 수 있습니다. 따라서 모델의 이해를 풍부하게 하는 추론 체인을 통합하는 것이 전반적인 정확도를 향상시킬 수 있습니다. 실험에서 Chain-of-Thought를 통합하는 것이 훈련의 강건성을 크게 향상시킨다는 것을 확인했습니다. GPT-4-1106를 사용하여 Chain-of-Thought 프롬프트를 생성하였으며, 사용된 프롬프트의 예시는 Figure 3에 제시되어 있습니다.
4.4. Qualitative Analysis
Figure 4에서는 RAFT와 DSF 모델의 비교적인 성능 차이를 보여줍니다. DSF 모델은 각본 작가의 신원을 묻는 질문에 혼란을 겪으며, 올바른 대답 대신 잘못된 영화를 인용합니다. 그러나 RAFT 모델은 질문에 정확히 답변합니다. 이 차이는 질문-답변 쌍만을 사용하여 모델을 훈련시키는 것이 제공된 문서에서 관련 문맥을 도출하는 능력을 저해할 수 있음을 시사합니다. 이러한 비교는 모델이 텍스트를 효과적으로 처리하고 이해하기 위해 표준 교육 튜닝과 문맥 이해를 통합하는 것의 중요성을 강조합니다.
4.5. Should we train the LLM always with the oracle context for RAG?
대규모 언어 모델(LLM)을 훈련시킬 때 항상 오라클 문맥을 사용해야 하는가에 대한 탐구에서, 우리는 훈련 데이터에 오라클 문서를 포함해야 하는 비율(p%)에 대해 탐구합니다. 우리의 연구 결과는 모델의 성능을 향상시키기 위해 오라클 문서를 100% 포함시킬 필요는 없다는 것을 보여줍니다. 오히려, 오라클 문서를 배제한 일부 훈련 데이터(p=80%)를 사용하는 것이 RAG 작업에서 모델의 성능을 향상시킬 수 있다는 것을 발견했습니다. 최적의 비율은 데이터셋에 따라 다르며, figure5에 그 결과를 나타내고 있습니다. 결과적으로 오라클 문서를 포함한 훈련 데이터의 일부를 사용하여 모델을 훈련시키고, 테스트 시에는 오라클 문서와 방해 문서를 함께 제공하여 이 방식을 유지합니다. 이러한 결과는 도메인 특정 RAG 작업에서 문맥에서 오라클 문서를 배제한 훈련 데이터의 사용이 유용하다는 것을 나타냅니다.
5. RAFT Generalizes to Top-K RAG
RAFT의 다양한 평가 지표에 대한 성능을 시연한 후, 이제 RAFT에 포함된 방해 문서의 수가 RAG 결과 및 모델의 성능에 어떤 영향을 미치는지를 연구합니다. 이전 연구에서는 대규모 언어 모델(LLM)이 관련 없는 텍스트에 취약하다는 것을 강조했습니다(Shi et al., 2023a; Weston & Sukhbaatar, 2023; Liu et al., 2023b). 이 문제는 특히 상위 k RAG가 빈번하게 사용되는 상황에서 매우 중요합니다. 이러한 상황에서 모델은 관련 없는 콘텐츠를 식별하고 무시하며, 관련 정보에만 집중할 수 있는 능력이 필요합니다.
5.1. Making Model Robust to top-K RAG
대규모 언어 모델(LLM)이 검색 파이프라인 내에서 관련 없는 텍스트를 걸러내는 능력을 향상시키는 문제에 대응하기 위해, 우리는 오라클(매우 관련 있는) 문서만을 사용하여 훈련하는 것이 모델이 관련 없는 정보를 식별하고 무시하는 능력을 약화시킬 수 있음을 밝혀냈습니다. 이를 해결하기 위해, 우리의 알고리즘인 RAFT는 오라클 문서와 관련 없는 문서를 혼합한 전략을 채택합니다. 이러한 방법론은 관련 없는 문서의 적절한 비율을 조사하고, 검색 증가 생성(RAG) 중에 테스트 단계에서 만난 다양한 양의 문서에 이 훈련 접근 방식이 얼마나 잘 적응하는지를 평가합니다. 이를 통해 우리는 모델이 적절한 콘텐츠를 식별하고 활용하는 효율성을 강화하기 위해 관련 있는 정보와 관련 없는 정보 사이의 균형을 정교화하고자 합니다.
참고로 4.5절은 훈련 데이터의 P%가 방해 요소를 포함해야 하는지에 대해 살펴보았지만, 이 섹션에서는 테스트 시나리오를 연구합니다.
Training with Negative Documents
대규모 언어 모델(LLM)이 검색된 문서에서의 관련 없는 텍스트에 대한 강건성을 향상시키기 위해, 우리는 golden(매우 관련 있는) 문서와 distractor(관련 없는) 문서를 모두 포함하는 파인튜닝 접근 방식을 채택했습니다. 모델은 다양한 수의 디스트랙터 문서와 함께 훈련되었지만, 검색된 상위 k개 문서를 사용하여 일관되게 평가되었습니다(이는 p와 다릅니다.). 우리의 연구 결과는 Fig. 6에 자세히 나와 있으며, 오라클 문서만을 사용하여 파인튜닝하는 것은 종종 디스트랙터 문서를 포함한 설정과 비교하여 성능이 떨어지는 결과를 낳는다는 것을 보여줍니다. 이 통찰력은 특히 우리의 알고리즘인 RAFT에 매우 유익했습니다. 실험에서는 일반적으로 하나의 오라클 문서와 네 개의 디스트랙터 문서로 구성된 훈련 설정을 사용합니다. 이 접근 방식은 모델이 디스트랙터에 압도되지 않으면서도 관련 있는 정보를 효과적으로 식별하고 우선 순위를 정하는 능력을 갖게 합니다.


Generalization to a variable number of test-time documents. 연구의 확장으로, 모델의 성능에 미치는 다양한 양의 시험용 문서의 영향을 조사했습니다. 실험은 다양한 수의 distractor 문서로 훈련된 모델이 시험 시 문서 수의 변화에 어떻게 반응하는지 평가했습니다. Fig. 6의 결과는 훈련 중에 distractor 문서를 포함하는 것이 시험 중에 문서 수의 변화에 더 견고한 모델을 만든다는 것을 확인합니다. 이 능력은 우리의 접근 방식인 RAFT의 견고성을 더욱 뒷받침합니다. 결과는 모델을 다양한 실제 시나리오에 대비하기 위해 잘 보정된 훈련 환경의 중요성을 강조합니다.
6. Related Works
Retrieval-Augmented Language Models RAG은 외부 지식 베이스에서 관련 정보를 가져와 언어 모델의 성능을 향상시키는 것으로 알려져 있습니다. 이는 다양한 자연어 처리(NLP) 작업에서 성능을 향상시킵니다. 이 통합은 "검색 및 읽기" 패러다임을 따르며, 검색 모듈이 외부 소스에서 추가적인 컨텍스트를 제공하고, 이를 사용하여 언어 모델이 최종 출력을 생성합니다. 검색 프로세스는 입력을 쿼리로 사용하여 문서를 가져오고, 언어 모델은 이를 최종 예측에 통합합니다. 이러한 통합 방법에는 Atlas, RETRO, kNN-LM, 그리고 Shi 등이 있습니다.


Memorization 대규모 신경 언어 모델에 대한 중요한 질문 중 하나는 모델이 텍스트를 "이해"하는지(Feldman, 2020; Power 등, 2022) 아니면 단순히 표면적인 패턴 기억에 의존하는지(Carlini 등, 2019; Tänzer 등, 2022)에 대한 것입니다. 이에 관한 연구들은 모델에서 기억의 정도를 양적으로 측정하는 방법론을 개발했으며, 기억이 모델의 일반화 능력에 어떤 영향을 미치는지를 탐구했다. 최근 연구는 언어 모델이 훈련 데이터를 기억하고 재현하는 능력을 입증함으로써 상당한 개인 정보 보호 우려가 제기되었습니다.
Finetuning of LLMs 최근 몇 년간 대규모 언어 모델(LLMs)의 발전에는 급격한 진전이 있었습니다(Brown et al., 2020; OpenAI, 2023; Workshop et al., 2022; Touvron et al., 2023; Anil et al., 2023). 이러한 기반 모델은 하류 작업에 적응하기 위해 세밀 조정(fine-tuning)이 널리 사용되고 있습니다(Mishra et al., 2021; Sanh et al., 2021; Chung et al., 2022; Muennighoff et al., 2023; Zhou et al., 2023b; Lin et al., 2023b; Ji et al., 2024). 전통적인 supervised fine-tuning은 비용과 계산 능력의 제약으로 제한될 수 있으므로, 매개 변수 효율적인 세밀 조정(Houlsby et al., 2019), Prompt Tuning(Lester et al., 2021), Prefix-Tuning(Li & Liang, 2021), P-Tuning(Liu et al., 2022a) 및 저위험 기반 세밀 조정(Hu et al., 2021)과 같은 새로운 기법이 주목을 받고 있습니다. 이러한 방법은 언어 모델이 도메인 특화 지식을 습득하고 질문 응답, 요약 및 대화 생성과 같은 특수 작업에 적응할 수 있도록 합니다. 또한, RLHF(Ouyang et al., 2022; Rafailov et al., 2023; Liu et al., 2023a; Zhang et al., 2023)를 통한 강화 학습은 언어 모델의 선호도를 인간과 일치시키는 것을 목표로 합니다.
Finetuning for RAG 최근 논문들은 세밀 조정을 통해 사전 학습된 대규모 언어 모델(LLM)이 RAG 작업에서 더 나은 성능을 발휘하도록 탐구하고 있습니다.(Lin et al., 2023a; Wang et al., 2023; Xu et al., 2023; Liu et al., 2024). 이러한 연구들은 RAG를 위한 세밀 조정 데이터셋을 구축하고 모델을 훈련하여 작업을 수행하는 데 초점을 맞추고 있습니다. 특히, 테스트 시 도메인이나 문서가 훈련 시와 다를 수 있는 설정에서 이들 작업을 수행하고 있지만, 현 논문은 테스트 시에는 동일한 문서 세트에 대해 LLM을 테스트하는 것에만 초점을 맞추고 있습니다.
7. Conclusion
RAFT는 "오픈북" 설정에서 특정 도메인에서 질문에 대한 모델의 성능을 향상시키기 위한 훈련 전략으로 설계되었습니다. 이 기술은 선택된 문서 모음을 기반으로 한 질문 응답 작업을 위한 LLMs의 세밀 조정 방법을 제시합니다. RAFT는 분산자 문서와 함께 모델을 훈련시키고, 일부 데이터셋은 문맥에서 오라클 문서를 제외하여 조직화합니다. 또한, 관련 텍스트에서 직접 인용구를 사용하여 사고 체인 방식으로 답변을 정리합니다. PubMed, HotpotQA 및 Gorilla API Bench에서의 평가는 RAFT의 중요한 잠재력을 강조하며, 도메인 특정 지식을 활용하는 영역 내 검색 증강 생성(RAG)이 계속해서 관심을 받을 것으로 예상됩니다. RAFT는 도메인별 지식을 활용하여 질문에 답하는 실제 시나리오를 다루며, 작은 세밀 조정된 모델이 일반적인 LLM 대비 유사한 성능을 발휘할 수 있다는 결과를 보여줍니다.
실제로 공부하던 중 도메인 adapting LLMs 생성이 가장 큰 관심사였는데, 새로운 관점에서 실험해볼 수 있을 것 같아 흥미로웠습니다.
다만, github가 제공되어있지만, 실제 도메인 데이터를 가지고 관련 코드를 어떻게 활용하면 좋을 지 조금 더 연구가 필요할 것 같습니다.
RAFT 논문
https://arxiv.org/abs/2403.10131?utm_source=pytorchkr
RAFT 소개글
https://gorilla.cs.berkeley.edu/blogs/9_raft.html?utm_source=pytorchkr
GITHUB
https://github.com/ShishirPatil/gorilla/tree/main/raft?utm_source=pytorchkr
'논문 요약' 카테고리의 다른 글
| [NLP] Transformer (Attention Is All You Need) (0) | 2024.05.02 |
|---|---|
| [연구 논문] 연구 논문(research paper) 읽는 법 (0) | 2024.04.03 |
| [리뷰 논문] 리뷰 논문(review paper) 읽는 법 (0) | 2024.04.02 |


